Django Under Hood #02: Django’s ORM Query Compiler—From QuerySet to SQL

Part 2 of the “Django Under the Hood” series — deep dives into Django’s internals, edge cases, and the mechanics that separate production-grade applications from tutorial code.
User.objects.filter(is_active=True).exclude(last_login=None).order_by('-date_joined')[:10]
This line doesn’t touch your database.
Not the filter(). Not the exclude(). Not the order_by(). Not even the slice.
Django’s ORM is lazy. Aggressively lazy. It builds a query specification, passes it through a compiler, generates SQL, and executes it — but only when absolutely necessary.
Understanding this pipeline is the difference between writing code that looks clean but runs 400 queries, and code that looks identical but runs 2.
Let’s trace what happens from Model.objects to the SQL that hits your database.
The Manager: Where It Starts
User.objects.filter(is_active=True)
objects is a Manager. It's a class attribute, but accessing it returns something unexpected:
# django/db/models/manager.py
class Manager(BaseManager.from_queryset(QuerySet)):
pass
class BaseManager:
def __get__(self, obj, cls=None):
if obj is not None:
raise AttributeError("Manager isn't accessible via model instances")
return self # Returns the manager, bound to the model class
The manager is a descriptor. When you access User.objects, Python calls __get__, which returns the manager itself. The manager knows which model it belongs to.
# What you write
User.objects.filter(is_active=True)
# What actually happens
manager = User.__class__.__dict__['objects'].__get__(None, User)
queryset = manager.filter(is_active=True)
Every Manager method that queries data returns a QuerySet:
class BaseManager:
def get_queryset(self):
return self._queryset_class(model=self.model, using=self._db)
def filter(self, *args, **kwargs):
return self.get_queryset().filter(*args, **kwargs)
def all(self):
return self.get_queryset()
QuerySet: The Specification Object
A QuerySet is not a list. It's not results. It's a specification of a query that hasn't run yet.
# django/db/models/query.py
class QuerySet:
def __init__(self, model=None, query=None, using=None):
self.model = model
self._db = using
self.query = query or sql.Query(self.model) # The actual query builder
self._result_cache = None # Results stored here after execution
self._prefetch_related_lookups = ()
The critical attribute is self.query — an instance of sql.Query. This is where the actual query specification lives.
Chainable Methods Clone
Every filter, exclude, order_by returns a new QuerySet:
class QuerySet:
def filter(self, *args, **kwargs):
clone = self._clone() # New QuerySet with copied query
clone.query.add_q(Q(*args, **kwargs))
return clone
def _clone(self):
c = self.__class__(
model=self.model,
query=self.query.chain(), # Deep copy of query
using=self._db,
)
c._prefetch_related_lookups = self._prefetch_related_lookups[:]
return c
This is why QuerySets are immutable. Each operation creates a new one:
qs1 = User.objects.filter(is_active=True)
qs2 = qs1.filter(is_staff=True) # qs1 unchanged
qs3 = qs1.exclude(last_login=None) # qs1 still unchanged
# qs1, qs2, qs3 are three different QuerySets
The Query Object: Where SQL Lives
sql.Query is the internal representation of a database query:
# django/db/models/sql/query.py
class Query:
def __init__(self, model):
self.model = model
self.alias_map = {} # Table aliases
self.where = WhereNode() # WHERE clause tree
self.select = [] # SELECT columns
self.tables = [] # FROM tables
self.order_by = [] # ORDER BY columns
self.group_by = None # GROUP BY columns
self.distinct = False # DISTINCT flag
self.select_related = {} # JOIN specifications
self.max_depth = 5 # select_related depth limit
self.low_mark = 0 # OFFSET
self.high_mark = None # LIMIT
self.annotations = {} # Aggregations/annotations
When you call .filter(is_active=True):
def add_q(self, q_object):
# q_object is Q(is_active=True)
clause, _ = self._add_q(q_object, self.used_aliases)
self.where.add(clause, AND)
The WhereNode is a tree structure:
# After: User.objects.filter(is_active=True).exclude(last_login=None)
where = WhereNode(
connector=AND,
children=[
Exact(lhs=Col('is_active'), rhs=True), # is_active = True
WhereNode(
connector=AND,
negated=True, # exclude() sets this
children=[
IsNull(lhs=Col('last_login'), rhs=True), # last_login IS NULL
]
)
]
)
# Becomes: WHERE is_active = True AND NOT (last_login IS NULL)
Lazy Evaluation: When Queries Actually Run
QuerySets are lazy. They execute only when you “consume” them:
# These do NOT execute queries:
qs = User.objects.filter(is_active=True)
qs = qs.exclude(last_login=None)
qs = qs.order_by('-date_joined')
qs = qs[:10]
# These DO execute queries:
list(qs) # Iteration
len(qs) # Length (use .count() instead!)
qs[0] # Indexing
bool(qs) # Boolean evaluation (use .exists() instead!)
repr(qs) # Printing in shell
for user in qs: # Iteration
pass
The magic happens in __iter__:
class QuerySet:
def __iter__(self):
self._fetch_all() # Execute query, fill cache
return iter(self._result_cache)
def _fetch_all(self):
if self._result_cache is None:
self._result_cache = list(self._iterable_class(self))
_iterable_class is typically ModelIterable, which:
- Compiles the query to SQL
- Executes it against the database
- Converts rows to model instances
The Compiler: Query to SQL
When a QuerySet executes, it calls the compiler:
# django/db/models/sql/query.py
class Query:
def get_compiler(self, using=None):
connection = connections[using or DEFAULT_DB_ALIAS]
return connection.ops.compiler('SQLCompiler')(self, connection, using)
Different databases get different compilers:
# PostgreSQL: django.db.backends.postgresql.compiler.SQLCompiler
# MySQL: django.db.backends.mysql.compiler.SQLCompiler
# SQLite: django.db.backends.sqlite3.compiler.SQLCompiler
The compiler translates the Query object to database-specific SQL:
# django/db/models/sql/compiler.py
class SQLCompiler:
def as_sql(self):
# Build SELECT clause
out_cols = self.get_select()
# Build FROM clause with JOINs
from_, params = self.get_from_clause()
# Build WHERE clause
where, w_params = self.compile(self.where)
# Build ORDER BY
ordering = self.get_ordering()
# Assemble final SQL
sql = 'SELECT %s FROM %s' % (', '.join(out_cols), from_)
if where:
sql += ' WHERE %s' % where
if ordering:
sql += ' ORDER BY %s' % ', '.join(ordering)
return sql, params
Example Compilation
User.objects.filter(is_active=True, date_joined__year=2024).order_by('-date_joined')[:10]
Query object state:
Query(
model=User,
where=WhereNode(
children=[
Exact(Col('is_active'), True),
Exact(Extract('year', Col('date_joined')), 2024),
]
),
order_by=['-date_joined'],
low_mark=0,
high_mark=10,
)
Compiled SQL (PostgreSQL):
SELECT "auth_user"."id", "auth_user"."username", "auth_user"."email", ...
FROM "auth_user"
WHERE "auth_user"."is_active" = true
AND EXTRACT('year' FROM "auth_user"."date_joined") = 2024
ORDER BY "auth_user"."date_joined" DESC
LIMIT 10
Lookups: The __ Magic
How does date_joined__year=2024 become EXTRACT('year' FROM ...)?
Django’s lookup system:
# django/db/models/lookups.py
class Lookup:
def as_sql(self, compiler, connection):
raise NotImplementedError
class Exact(Lookup):
lookup_name = 'exact'
def as_sql(self, compiler, connection):
lhs_sql, lhs_params = self.process_lhs(compiler, connection)
rhs_sql, rhs_params = self.process_rhs(compiler, connection)
return f'{lhs_sql} = {rhs_sql}', lhs_params + rhs_params
When you write field__lookup=value, Django:
- Splits on
__to find field path and lookup name - Resolves field path through relations
- Finds the lookup class by name
- Creates a lookup instance
# Parsing 'date_joined__year'
parts = 'date_joined__year'.split('__')
# ['date_joined', 'year']
# 'date_joined' -> Field
# 'year' -> Transform (ExtractYear)
Transforms vs Lookups
Transforms modify the left-hand side:
date_joined__year # ExtractYear transform
name__lower # Lower transform
Lookups are comparisons:
name__iexact # Case-insensitive exact
date__gte # Greater than or equal
tags__contains # Array contains (PostgreSQL)
Transforms can chain, lookups terminate:
# Valid: transform -> transform -> lookup
name__lower__startswith='john'
# Invalid: lookup -> anything
name__iexact__lower # iexact is a lookup, can't chain
JOINs: select_related Internals
Book.objects.select_related('author', 'publisher').filter(title__startswith='Django')
select_related adds JOINs to the query:
class Query:
def add_select_related(self, fields):
if self.select_related is True:
# select_related() with no args means "all"
return
for field in fields:
# Build path through relations
self.select_related[field] = {} # Nested dict for path
The compiler generates JOINs:
class SQLCompiler:
def get_from_clause(self):
result = [self.quote_name(self.query.model._meta.db_table)]
for alias, join in self.query.alias_map.items():
result.append(
'%s %s ON (%s)' % (
join.join_type, # 'INNER JOIN' or 'LEFT OUTER JOIN'
self.quote_name(join.table_name),
join.on_clause,
)
)
return ' '.join(result)
Result:
SELECT "book"."id", "book"."title",
"author"."id", "author"."name",
"publisher"."id", "publisher"."name"
FROM "book"
INNER JOIN "author" ON ("book"."author_id" = "author"."id")
INNER JOIN "publisher" ON ("book"."publisher_id" = "publisher"."id")
WHERE "book"."title" LIKE 'Django%'
Prefetch: The Separate Query Strategy
prefetch_related works differently — it runs separate queries:
Author.objects.prefetch_related('books')
# django/db/models/query.py
class QuerySet:
def _prefetch_related_objects(self):
prefetch_related_objects(self._result_cache, self._prefetch_related_lookups)
def prefetch_related_objects(model_instances, related_lookups):
for lookup in related_lookups:
# Get all primary keys from fetched objects
pks = [obj.pk for obj in model_instances]
# Run single query for related objects
related_qs = RelatedModel.objects.filter(foreign_key__in=pks)
# Build lookup dict
related_dict = defaultdict(list)
for obj in related_qs:
related_dict[obj.foreign_key_id].append(obj)
# Attach to original objects
for obj in model_instances:
setattr(obj, '_prefetched_objects_cache', {
lookup: related_dict[obj.pk]
})
Two queries total:
-- Query 1: Authors
SELECT * FROM "author"
-- Query 2: Books for all authors
SELECT * FROM "book" WHERE "book"."author_id" IN (1, 2, 3, 4, 5)
Prefetch Objects: Custom QuerySets
from django.db.models import Prefetch
Author.objects.prefetch_related(
Prefetch(
'books',
queryset=Book.objects.filter(published=True).order_by('-pub_date'),
to_attr='published_books' # Store in custom attribute
)
)
The Prefetch object controls the related query:
class Prefetch:
def __init__(self, lookup, queryset=None, to_attr=None):
self.prefetch_through = lookup # 'books'
self.queryset = queryset # Custom filtering
self.to_attr = to_attr # Where to store results
Annotations and Aggregations
from django.db.models import Count, Avg
Author.objects.annotate(
book_count=Count('books'),
avg_rating=Avg('books__rating')
)
Annotations add to the SELECT clause:
class Query:
def add_annotation(self, annotation, alias):
# annotation is Count('books')
self.annotations[alias] = annotation
The compiler includes them:
class SQLCompiler:
def get_select(self):
select = []
# Regular fields
for field in self.query.model._meta.fields:
select.append(Col(field))
# Annotations
for alias, annotation in self.query.annotations.items():
select.append((annotation, alias))
return select
Result:
SELECT "author"."id", "author"."name",
COUNT("book"."id") AS "book_count",
AVG("book"."rating") AS "avg_rating"
FROM "author"
LEFT OUTER JOIN "book" ON ("author"."id" = "book"."author_id")
GROUP BY "author"."id", "author"."name"
Notice the automatic GROUP BY — Django adds it when you use aggregation functions with annotations.
Subqueries: OuterRef and Subquery
from django.db.models import OuterRef, Subquery
newest_book = Book.objects.filter(
author=OuterRef('pk')
).order_by('-pub_date').values('title')[:1]
Author.objects.annotate(
latest_book=Subquery(newest_book)
)
OuterRef creates a reference to the outer query:
class OuterRef(F):
def resolve_expression(self, query, *args, **kwargs):
# Instead of resolving to a column in this query,
# return a reference to be resolved by the outer query
return ResolvedOuterRef(self.name)
The compiler handles the nesting:
SELECT "author"."id", "author"."name",
(SELECT "book"."title"
FROM "book"
WHERE "book"."author_id" = "author"."id" -- OuterRef resolved
ORDER BY "book"."pub_date" DESC
LIMIT 1
) AS "latest_book"
FROM "author"
Query Execution: The Final Step
After compilation, the query executes:
class SQLCompiler:
def execute_sql(self, result_type=MULTI):
sql, params = self.as_sql()
cursor = self.connection.cursor()
cursor.execute(sql, params)
if result_type == SINGLE:
return cursor.fetchone()
elif result_type == MULTI:
return cursor # For iteration
But there’s caching:
class QuerySet:
def __iter__(self):
self._fetch_all()
return iter(self._result_cache)
def _fetch_all(self):
if self._result_cache is None: # Only execute once!
self._result_cache = list(self._iterable_class(self))
Critical: Once a QuerySet is evaluated, results are cached. Re-iterating doesn’t hit the database:
qs = User.objects.filter(is_active=True)
# First iteration: executes query
for user in qs:
print(user)
# Second iteration: uses cache, no query
for user in qs:
print(user)
# But this creates a NEW QuerySet, so new query:
for user in User.objects.filter(is_active=True):
print(user)
The N+1 Problem: Mechanical Explanation
Now you understand why N+1 happens:
for author in Author.objects.all(): # Query 1
print(author.books.count()) # Query 2, 3, 4, ... N+1
Each author.books access:
- Creates a new QuerySet from the
RelatedManager - The QuerySet is not cached on the author instance
- Each iteration evaluates a fresh query
The fix makes mechanical sense now:
# prefetch_related caches related objects
authors = Author.objects.prefetch_related('books')
# Query 1: SELECT * FROM author
# Query 2: SELECT * FROM book WHERE author_id IN (...)
for author in authors:
# No query - books are in author._prefetched_objects_cache
print(len(author.books.all()))
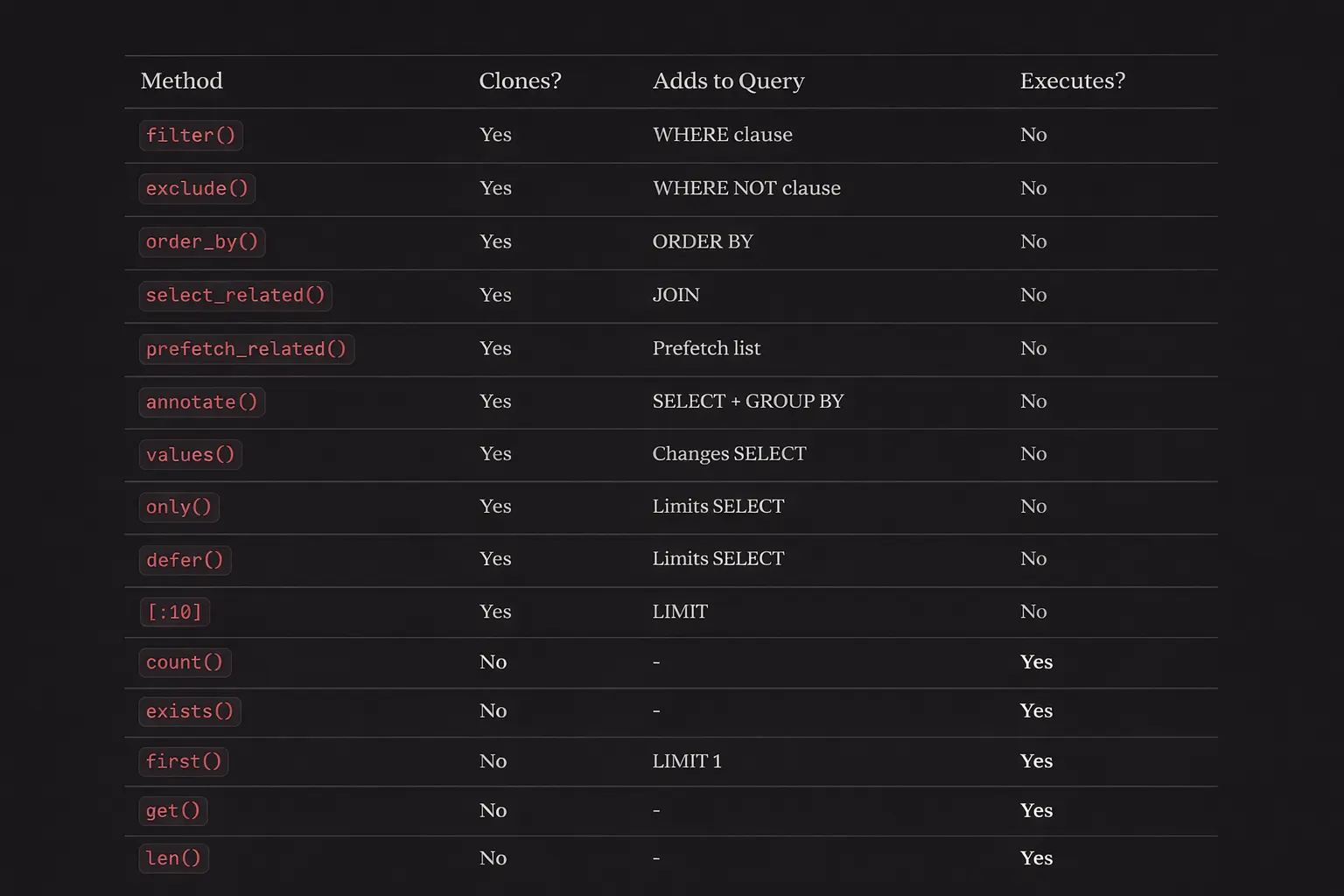
QuerySet Methods: What They Actually Do
Press enter or click to view image in full size
Debugging Query Generation
# See the SQL without executing
qs = User.objects.filter(is_active=True)
print(qs.query)
# With parameters (Django 4.2+)
print(qs.query.sql_with_params())
# Explain query plan
print(qs.explain())
# PostgreSQL specific
print(qs.explain(analyze=True, verbose=True))
For complex queries:
from django.db import connection
# Execute first
list(qs)
# See all queries run
for query in connection.queries:
print(query['sql'])
print(query['time'])
Performance Patterns from Understanding Internals
1. Reuse evaluated QuerySets:
# Bad: two queries
users = User.objects.filter(is_active=True)
count = users.count() # Query 1
data = list(users) # Query 2
# Good: one query
users = list(User.objects.filter(is_active=True))
count = len(users) # No query, just len()
2. Use iterator() for large datasets:
# Bad: loads all into memory
for user in User.objects.all(): # _result_cache holds millions
process(user)
# Good: streams from database
for user in User.objects.iterator(chunk_size=2000):
process(user) # Only 2000 in memory at a time
3. Use values() when you don’t need model instances:
# Bad: creates 10000 User objects with all fields
for user in User.objects.all():
print(user.id, user.email)
# Good: returns dicts, no model instantiation
for row in User.objects.values('id', 'email'):
print(row['id'], row['email'])
# Better: returns tuples, even lighter
for user_id, email in User.objects.values_list('id', 'email'):
print(user_id, email)
# Best for single field: flat list
emails = User.objects.values_list('email', flat=True)
# Returns: ['a@example.com', 'b@example.com', ...]
4. exists() vs count() vs bool():
# Bad: counts everything
if User.objects.filter(is_staff=True).count() > 0: # SELECT COUNT(*)
# Bad: fetches all objects
if User.objects.filter(is_staff=True): # SELECT * (then bool)
# Good: LIMIT 1
if User.objects.filter(is_staff=True).exists(): # SELECT 1 LIMIT 1
What’s Next
This was the ORM query compiler — from Manager to SQL.
Next in the series: Connection Management and the Database Wrapper — connection pooling, the connection lifecycle, atomic transactions, and what really happens when you call transaction.atomic().
Series: Django Under the Hood
- What Actually Happens When a Request Hits Your Server
- The ORM Query Compiler ← You are here
- Connection Management and the Database Wrapper (coming next)
- Signal Dispatch Internals
- Template Engine Compilation
- Form and Validation Pipeline
- Authentication Backend Chain
- Static Files and WhiteNoise Internals
- Migration System Deep Dive
- Test Client and Request Factory Mechanics
















